Builder¶
The Driver page covered the basics of building the Driver, visualizing the dataflow, and executing the dataflow. We learned how to create the dataflow by passing a Python module to Builder().with_modules().
On this page, how to configure your Driver with the driver.Builder(). There will be mentions of advanced concepts, which are further explained on their respective page.
Note
As your Builder code grows complex, defining it over multiple lines can improve readability. This is possible by using parentheses after the assignment =
dr = (
driver.Builder()
.with_modules(my_dataflow)
.build()
)
The order of Builder statements doesn’t matter as long as .build() is last.
with_modules()¶
This passes dataflow modules to the Driver. When passing multiple modules, the Driver assembles them into a single dataflow.
# my_dataflow.py
def A() -> int:
"""Constant value 35"""
return 35
def B(A: int) -> float:
"""Divide A by 3"""
return A / 3
# my_other_dataflow.py
def C(A: int, B: float) -> float:
"""Square A and multiply by B"""
return A**2 * B
# run.py
from hamilton import driver
import my_dataflow
import my_other_dataflow
dr = driver.Builder().with_modules(my_dataflow, my_other_dataflow).build()
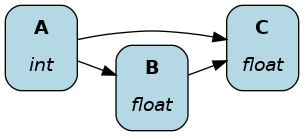
It encourages organizing code into logical modules (e.g., feature processing, model training, model evaluation). features.py might depend on PySpark and model_training.py on XGBoost. By organizing modules by dependencies, it’s easier to reuse the XGBoost model training module in a project that doesn’t use PySpark and avoid version conflicts.
# run.py
from hamilton import driver
import features
import model_training
import model_evaluation
dr = (
driver.Builder()
.with_modules(features, model_training, model_evaluation)
.build()
)
with_config()¶
This is directly related to the @config function decorator (see Select functions to include) and doesn’t have any effect in its absence. By passing a dictionary to with_config(), you configure which functions will be used to create the dataflow. You can’t change the config after the Driver is created. Instead, you need to rebuild the Driver with the new config values.
# my_dataflow.py
from hamilton.function_modifiers import config
def A() -> int:
"""Constant value 35"""
return 35
@config.when_not(version="remote")
def B__default(A: int) -> float:
"""Divide A by 3"""
return A / 3
@config.when(version="remote")
def B__remote(A: int) -> float:
"""Divide A by 2"""
return A / 2
# run.py
from hamilton import driver
import my_dataflow
dr = (
driver.Builder()
.with_modules(my_dataflow)
.with_config(dict(version="remote"))
.build()
)
with_adapters()¶
This allows to add multiple Lifecycle hooks to the Driver. This is a very flexible abstraction to develop custom plugins to do logging, telemetry, alerts, and more. The following adds a hook to launch debugger when reaching the node "B":
# run.py
from hamilton import driver, lifecycle
import my_dataflow
debug_hook = lifecycle.default.PDBDebugger(node_filter="B", during=True)
dr = (
driver.Builder()
.with_modules(my_dataflow)
.with_adapters(debug_hook)
.build()
)
Other hooks are available to output a progress bar in the terminal, do experiment tracking for your Hamilton runs, cache results to disk, send logs to DataDog, and more!
enable_dynamic_execution()¶
This directly relates to the Builder with_local_executor() and with_remote_executor() and the Parallelizable/Collect functions (see Dynamic DAGs/Parallel Execution). For the Driver to be able to parse them, you need to set allow_experimental_mode=True like the following:
# run.py
from hamilton import driver
import my_dataflow # <- this contains Parallelizable/Collect nodes
dr = (
driver.Builder()
.enable_dynamic_execution(allow_experimental_mode=True) # set True
.with_modules(my_dataflow)
.build()
)
By enabling dynamic execution, reasonable defaults are used for local and remote executors. You also specify them explicitly as such:
# run.py
from hamilton import driver
from hamilton.execution import executors
import my_dataflow
dr = (
driver.Builder()
.with_modules(my_dataflow)
.enable_dynamic_execution(allow_experimental_mode=True)
.with_local_executor(executors.SynchronousLocalTaskExecutor())
.with_remote_executor(executors.MultiProcessingExecutor(max_tasks=5))
.build()
)