Materialization¶
So far, we executed our dataflow using the Driver.execute() method, which can receive an inputs dictionary and return a results dictionary (by default). However, you can also execute code with Driver.materialize() to directly read from / write to external data sources (file, database, cloud data store).
On this page, you’ll learn:
The difference between
.execute()and.materialize()Why use materialization
What are DataSaver and DataLoader objects
The basics to write your own materializer
Different ways to write the same dataflow¶
Below are 3 ways to write a dataflow that:
loads a dataframe from a parquet file
preprocesses the dataframe
trains a machine learning model
saves the trained model
The first two options use Driver.execute() and the latter Driver.materialize(). Notice where in the code data is loaded and saved and how it affects the dataflow.
Nodes / dataflow context |
Driver context |
Materialization |
|---|---|---|
import pandas as pd
import xgboost
def raw_df(data_path: str) -> pd.DataFrame:
"""Load raw data from parquet file"""
return pd.read_parquet(data_path)
def preprocessed_df(raw_df: pd.DataFrame) -> pd.DataFrame:
"""preprocess raw data"""
return ...
def model(preprocessed_df: pd.DataFrame) -> xgboost.XGBModel:
"""Train model on preprocessed data"""
return ...
def save_model(model: xgboost.XGBModel, model_dir: str) -> None:
"""Save trained model to JSON format"""
model.save_model(f"{model_dir}/model.json")
if __name__ == "__main__":
import __main__
from hamilton import driver
dr = driver.Builder().with_modules(__main__).build()
data_path = "..."
model_dir = "..."
inputs = dict(data_path=data_path, model_dir=model_dir)
final_vars = ["save_model"]
results = dr.execute(final_vars, inputs=inputs)
# results["save_model"] == None
|
import pandas as pd
import xgboost
def preprocessed_df(raw_df: pd.DataFrame) -> pd.DataFrame:
"""preprocess raw data"""
return ...
def model(preprocessed_df: pd.DataFrame) -> xgboost.XGBModel:
"""Train model on preprocessed data"""
return ...
if __name__ == "__main__":
import __main__
from hamilton import driver
dr = driver.Builder().with_modules(__main__).build()
data_path = "..."
model_dir = "..."
inputs = dict(raw_df=pd.read_parquet(data_path))
final_vars = ["model"]
results = dr.execute(final_vars, inputs=inputs)
results["model"].save_model(f"{model_dir}/model.json")
|
import pandas as pd
import xgboost
def preprocessed_df(raw_df: pd.DataFrame) -> pd.DataFrame:
"""preprocess raw data"""
return ...
def model(preprocessed_df: pd.DataFrame) -> xgboost.XGBModel:
"""Train model on preprocessed data"""
return ...
if __name__ == "__main__":
import __main__
from hamilton import driver
from hamilton.io.materialization import from_, to
# this registers DataSaver and DataLoader objects
from hamilton.plugins import pandas_extensions, xgboost_extensions # noqa: F401
dr = driver.Builder().with_modules(__main__).build()
data_path = "..."
model_dir = "..."
materializers = [
from_.parquet(path=data_path, target="raw_df"),
to.json(path=f"{model_dir}/model.json", dependencies=["model"], id="model__json"),
]
dr.materialize(*materializers)
|
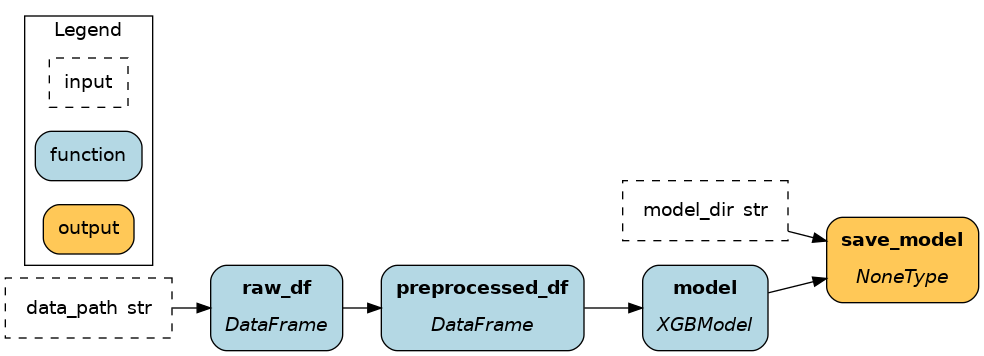
|
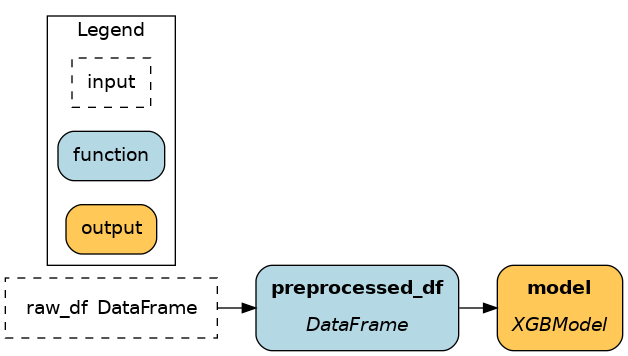
|
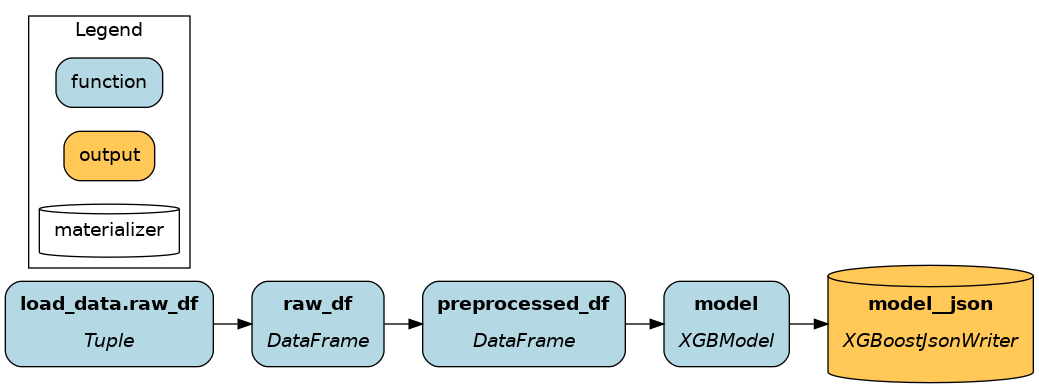
|
As explained previously, Driver.execute() walks the graph to compute the list of nodes you requested by name. For Driver.materialize(), you give it a list of data savers (from_) and data loaders (to). Each one will add a node to the dataflow before execution.
Note
Driver.materialize() can do everything Driver.execute() does, and more. It can receive inputs and overrides. Instead of using final_vars, you can use additional_vars to request nodes that you don’t want to materialize/save.
Why use materialization¶
Let’s compare the benefits of the 3 different approaches
Nodes / dataflow context¶
This approach defines data loading and saving as part of the dataflow and uses Driver.execute(). It is usually the simplest approach and the one you should start with.
Benefits
the functions
raw_df()andsave_model()are transparent as to how they load/save datacan easily change data location using the strings
data_pathandmodel_diras inputsall operations are part of the dataflow
Limitations
need to write a unique function for each loaded parquet file and saved model. To reduce code duplication, one could write a utility function
_load_parquet()can be too restrictive as to how to load data. Using
overridein the.execute()call can add flexibility.
Driver context¶
This approach loads and saves data outside the dataflow and uses Driver.execute(). Since the Driver is responsible for executing your dataflow, it makes sense to handle data loading/saving in the context of the “driver code” (e.g., run.py) if they change often.
Benefits
Driver users is responsible for loading/saving data
fewer dataflow functions to define and maintain
the functions for
raw_df()andsave_model()can live in another Python module that you can optionally build the Driver with.
Limitations
add complexity to the “driver code”.
lose the benefits of Hamilton for loading and saving operations (visualize, lifecycle hook, etc.)
to add flexibility to data loading/saving, one can adopt the nodes/dataflow context approach and add functions with
@configfor alternative implementations (see Select functions to include).
Materialization¶
This approach tries to strike a balance between the two previous methods and uses Driver.materialize().
Unique benefits
Use the Hamilton logic to combine nodes (more on that later)
Get tested code for common data loading and saving out-of-the-box (e.g., JSON, CSV, Parquet, pickle)
Easily save the same node to multiple formats
Benefits
Flexibility for Driver users to change data location
Less dataflow functions to define and maintain
All operations are part of the dataflow
Limitations
Writing a custom DataSaver or DataLoader requires more effort than adding a function to the dataflow.
Adds some complexity to the Driver (e.g.,
run.py).
DataLoader and DataSaver¶
In Hamilton, DataLoader and DataSaver are classes that define how to load or save a particular data format. Calling Driver.materialize(DataLoader(), DataSaver()) adds nodes to the dataflow (see visualizations above).
Here are simplified snippets for saving and loading an XGBoost model to/from JSON.
DataLoader
DataSaver
To define your own DataSaver and DataLoader, the Hamilton XGBoost extension provides a good example
@load_from and @save_to¶
Also, the data loaders and savers power the @load_from and @save_to Load and save external data